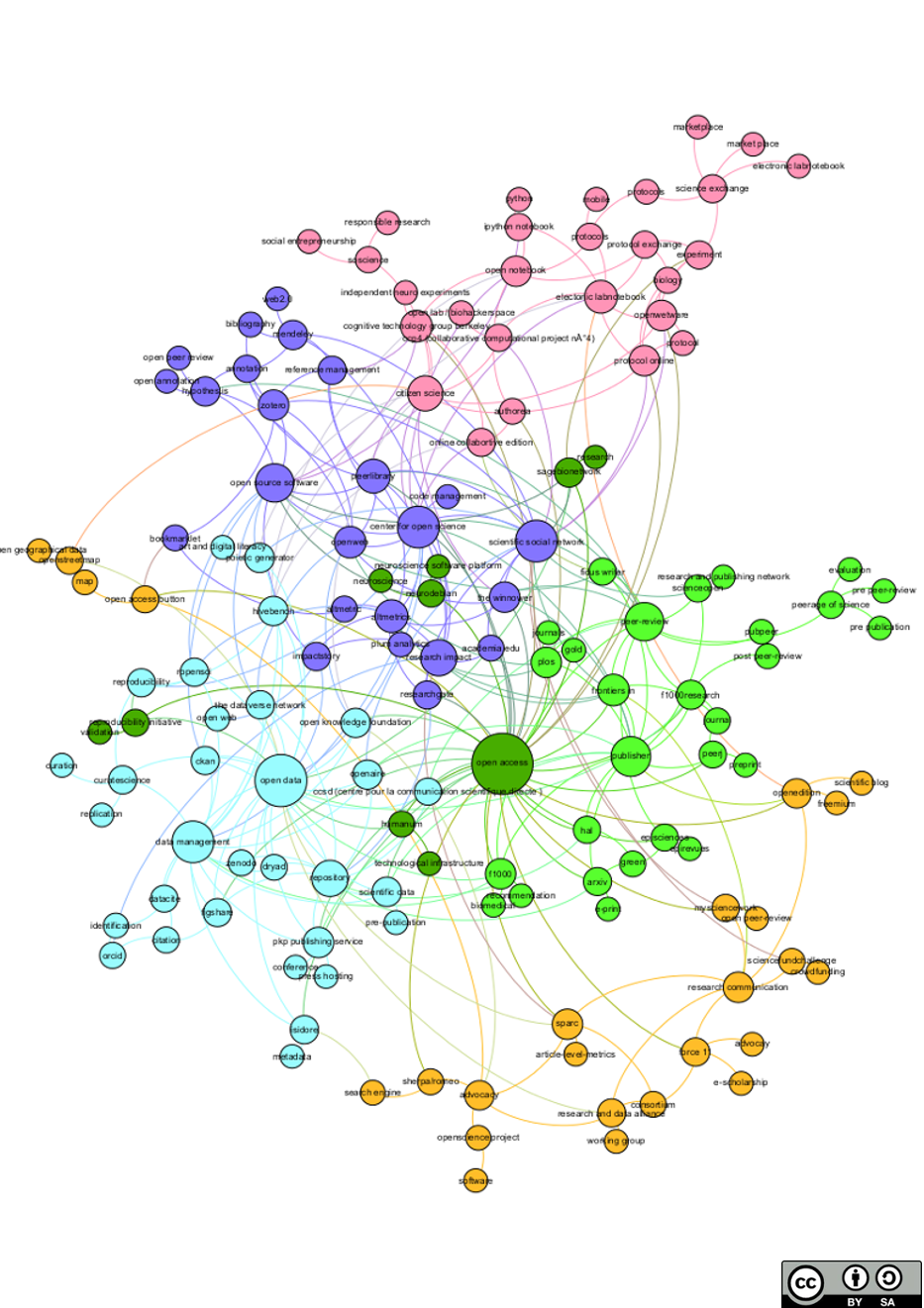
Dans le cadre d’Open experience, une première étape a été de mieux comprendre ce que l’Open Science représente dans le système de la recherche actuelle pour ainsi définir les différents acteurs et les services/actions/produits liés. Pour cela, nous avons mis au point une première cartographie de l’écosystème. Cette cartographie a été présentée lors d’Open Experience # 4 sur l’open Science et a nourri un débat fructueux sur la remise en cause de modèles économiques dominants et des premières tentatives de nouveaux modèles avec l’Open Science.
La recherche aujourd’hui : De la Science 2.0 à l’Open Science ?
Aujourd’hui, il paraît clair que le Web notamment coopératif (Web2.0) a transformé nos façons de consommer, de produire, d’échanger. Certains parlent même d’un nouvel Âge (Âge de la multitude, Âge de l’Accès). Le monde de la recherche et de la production des savoirs dits académiques n’échappent pas à ces transformations.
Le Web et plus largement les technologies de l’information et de la communication (TIC) donnent la possibilité de mettre en ligne des articles scientifiques, de stocker des données, du code sur le Web et de pouvoir les partager et les échanger beaucoup plus facilement pour un coût (qui pourrait être) presque nul. On regroupe parfois ce nouveau champ d’usage et de pratiques sous le terme de « Sciences 2.0 ».
Or, cette possibilité de rendre disponible à tous des connaissances sur le Web a aussi mis en lumière des phénomènes de privatisation des savoirs basés sur les droits de propriété intellectuelle, les brevets ou bien encore des monopoles d’entreprises privés ( industries pharmaceutiques, éditeurs scientifiques).
L’organisation du système de la recherche et de l’innovation actuelle, guidée par la valorisation des travaux de recherche pour s’insérer dans une économie des connaissances a fait également émerger un système “concurrentiel” ( en fait, de “rivalité”) pour obtenir des financements dans le cadre d’appels à propositions, de « grants ». Pour les chercheurs cela se traduit par une course aux publications sur laquelle ils sont évalués – phénomène du « publish or perish ». L’incitation à un travail collaboratif et au partage des connaissances se trouve alors fortement réduit.
En réaction, l’expression Open Science a été de plus en plus utilisée ces dernières années. Ce terme peut paraître tautologique. “La Science ne se devrait elle pas d’être ouverte?”. il insiste ainsi sur un système où les connaissances sont considérées comme un bien marchand dont la valeur est à capter.
L’Open Science prend aujourd’hui la forme d’un mouvement dont le but est de rendre la recherche plus transparente, ouverte et collaborative et de faciliter également les interactions entre Science et Société. L’Open Science est proche des mouvements autour des biens communs, renouvelés par les enjeux soulevés par les biens communs informationnels ou cognitifs.
Derrière ce terme rassembleur se regroupe un ensemble d’initiatives diverses de par les services proposés ou les structures qui les sous-tendent ( entreprises, associations, collectifs). Les Sciences 2.0 et l’Open Science ont amené à la création d’entreprises (startups) digitales, de collectifs académiques et non académiques (advocacy), de nouvelles infrastructures de recherche. Ces acteurs et ces pratiques poussent à transformer le système de la recherche. Ils amènent aussi à remettre en question les modèles économiques existants et à se questionner sur des nouveaux.
Un premier pas : cartographier l’écosystème de l’OpenScience
Fortement associée à la Science 2.0, le mouvemement de l’Open Science est marquée par une “forme réseau” . Afin de mieux comprendre les transformations de la recherche, il nous a semblé important de développer une approche systémique pour comprendre les interdépendances et les co-évolutions de ce système.
Pour cela, nous avons réalisé un premier essai de cartographie des acteurs liés à l’Open Science. Grâce à un questionnaire diffusé en ligne, 66 initiatives ont été répertoriées du 10 mai au 14 juin par 15 contributeurs. Pour chaque initiative, la date de création, le(s) services proposés ainsi que des mots clefs associés ont été complétés. Les données fournies par l’association Givewell “OpenScienceField” ont été aussi intégrées. A partir de la base de données initiale ainsi élaborée (tableau sous format tableur), nous avons construit une base de données de relations (i.e. structure nœuds-liens, nécessaire à l’analyse structurale de réseau et à la cartographie). Des cartes de réseaux de relations ont ensuite été généré grâce à Gephi (algorithme ForceAtlas) avec la mise en évidence de cluster (algorithme Modularity). Sur ces cartes sont ainsi représentées à la fois les initiatives Open Science et les mots clefs et nom de services qui leur sont associés.
Sur cette carte, cinq clusters principaux se dégagent.
- Le cluster vert correspond à l’Open Access c’est à dire l’accès en ligne et gratuit aux publications scientifiques associé au processus de peer reviewing (évaluation par les pairs). L’Open Access semble être au coeur de l’écosystème Open Science. Le mouvement de l’Open Access s’est développé depuis plus d’une dizaine d’année. Il a été l’une des premières revendications de la part des chercheurs face aux monopoles d’éditeurs scientifiques tels que Elsevier (cf The Cost of Knowledge). Des initiatives Non-Profit (PLOS) et for profit (PeerJ) autour de cette thématique se sont mis en place ( avec notamment en France HAL, archive ouverte nationale). En lien avec l’Open Access l’activité de peer-review est intimement lié avec des initiatives cherchant à le modifier ou le compléter par exemple l’Open Peer Review (F1000) ou le post Peer-Review (PubPeer).
- L’autre cluster qui se dessine (en bleu clair) est celui en lien avec l’ouverture des données de la recherche scientifique et de sa gestion La notion d’Open Data vient étendre le champ de l’Open Access qui désigne les publications scientifiques. L’Open Data concerne le partage des données de la recherche (données brutes, figures, photos etc..) mais aussi leur stockage. C’est autour de la gestion de ses données que des plateformes privées (Figshare) mais aussi universitaires (TheDataverse Network), nationale (HumaNum) ou internationale (Zenodo) se sont mises en place. Le cluster Open Access et Open Data se rejoignent notamment par rapport aux infrastructures de recherche à développer. C’est ainsi que des initiatives concernant la gestion de ces infrastructures se trouvent à la jonction sur la cartographie (CCSD en France ou Open Aire en Europe). Ces deux notions vont certainement être de plus en plus intimement liées mais également les modèles économiques des entreprises.
- Un cluster (bleu foncé) également important regroupe des initiatives de gestion de références bibliographiques, de réseaux sociaux scientifiques mais aussi de métriques alternatives (altmetrics). L’ensemble de ces initiatives ont pour point commun de gérer la réputation des chercheurs dans le monde de la recherche. Les méthodes plus traditionnelles sont mises en évidence par la gestion bibliographiques (Zotero, Mendeley outils de référencement “classique” des articles et des auteurs), mais aussi des nouveaux systèmes tels que les altmetrics (Impact Story, Plum Analytics) qui offrent d’autres critères de réputation autour des articles. Sont représentés aussi les réseaux sociaux scientifiques qui mettent en contact directement les chercheurs.
- Le cluster rose correspond à l’ouverture du processus de la recherche et à de nouvelles configurations de recherche avec l’intégration de non professionnels de la recherche. Il prend ainsi en compte la dimension sociétale associée à l’Open Science. Les Citizen Science sont un des premiers chaînons représentatifs des interactions science/société. La recherche responsable met en avant les contacts avec les entrepreneurs sociaux. Sont aussi présents dans ce cluster des nouveaux espaces de recherche tels que les biohackerspaces ou les open lab. En lien, on retrouve les carnets de recherche ouverts, Open Notebook qui offrent des outils permettant l’ouverture du processus de recherche (Ipython Notebook, protocol exchange).
- Le dernier cluster (jaune) regroupe quand à lui les initiatives qui communiquent autour de l’Open Science (Force 11) de l’Open Access ( SPARC) et sur la recherche en général.
Cette cartographie est un premier travail de recherche qui emprunte lui même une démarche Open Science. Par cette article et la présentation de ce projet le 17 juin, c’est une recherche en train de se faire qui est montrée pour qu’elle puisse être commentée, critiquée pour être ensuite affinée.
Par vos commentaires et vos remarques sur cette cartographie ou sur le questionnaire, cette recherche va pouvoir s’étoffer (ajout d’initiatives) et donner naissance à une cartographie qui sera croisée avec d’autres méthodologies et données au cours d’un travail de thèse pour mieux comprendre cet écosystème, sa dynamique et son impact sur le système de la recherche actuelle.
Remerciement à Franck Ghitalla pour la réalisation de la cartographie et Pascal Jollivet-Courtois pour l’aide à l’analyse des données et la relecture précieuse.


sujet très interessant.
Une question : dans cette mouvance « science 2.0 », par quels moyens les propositions d’avancées scientifiques sont elles validées ? n’y a-t-il pas un risque de nivellement par le bas où, sans système de validation par les pairs, et par une diffusion directe de ces savoirs, on fasse l’impasse sur la qualité – très variable – de ces savoirs.
Actuellement, les recherche reconnues restent diffusées à travers un système classique de « revues » scientifiques gérées par les pairs, tandis que le « tout-venant » ou les brouillons sont facilement téléchargeables mais, au final, de peu d’interet.
Les pépites exploitables sont alors noyées dans une masse informe de données.
Bravo pour ce travail de recherche.